



 Introduction
Introduction
In the present chapter, a much more powerful way of working with Java XML data called Document Object Model(DOM) will be discussed. DOM is very flexible and powerful and provides a much better way of working with XML data from a flexibility stand point than many other methods.
The DOM was adopted by W3C as a standard in 1998 and there are several revisions since then. The DOM provides a standardized way of discovering, manipulating and changing the content of a document using common programming techniques that are probably used in languages like JavaScript or C++ or C#.
Description
DOM is platform browser and language neutral. It does not assume anything about what platform is running on what browser turning on and there are several language implementations of the DOM that can be used to work with. One of the most common languages that people work with the DOM is JavaScript.
Using xml dom the consumer can upload, edit, remove, or move nodes within the tree at any point with a view to create an utility.
- DOM parser is very easy to use.
- It is more flexible to insert/delete nodes and traverse in any direction.
- Java DOM Parser is slower.
- It needs more memory space because the whole XML needs to be loaded into memory but could be too much overhead for large documents.
Description
The DOM represents DOM as a tree structure which is called as
node-tree structure and allows access to the objects in the tree using a set of programming functions and properties. All the XML content such as elements, comments, processing instructions, CDATA sections are presented as objects. These objects are generically referred to as Nodes. Notice that they are not called as elements. An element is a type of node.
DOM Theory : In the DOM, everything in an XML Document is a node i.e. the entire document is a document node.
- The text in the XML elements are the text nodes.
- Every XML element is an element node.
- Comments are comment nodes.
- Every attribute is an attribute node.
- Document interface, element interface, Attr(attribute) interface inherits from(extends) Node
- Node interface is the superinterface.
parent-child relationship.
The terms parent, child, and sibling defines the relationships in DOM Tree. Parent nodes have children. Children on the same level are called Siblings. Every node, except the root, has exactly one parent node. A node can have any number of children and Siblings can be referred as nodes with same parent. To access child nodes, use the method getNodeName(), getAttribute(), getElementByTagName(). Example
Below is the basic example for Java XML DOM Parser.
Step-1: Initially, the packages that are related to XML are imported.
[java]
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;
[/java]
inside the above code, org.w3c.dom characterizes the dom programming interfaces for xml records focused by w3c and javax.xml.parsers characterizes documentbuilderfactory tastefulness and documentbuilder polish, which gives back a thing that actualizes w3c record interface. this package likewise characterizes parserconfigurationexception style for reporting botches.
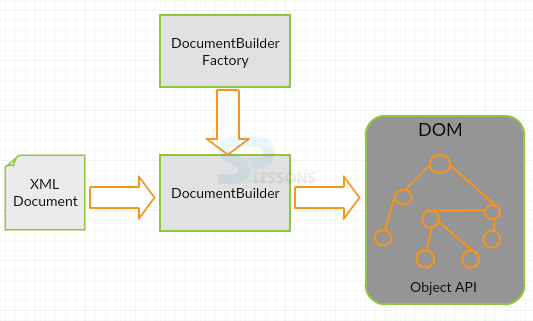 Step-2: Then create the above mentioned DocumentBuilderFactory class and DocumentBuilder class.
[java]
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
[/java]
Step-3: A XML document should be created from file or a stream. In the below code,
Step-2: Then create the above mentioned DocumentBuilderFactory class and DocumentBuilder class.
[java]
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
[/java]
Step-3: A XML document should be created from file or a stream. In the below code,
parse() is used to parse document.
[java]
StringBuilder xmlStringBuilder = new StringBuilder();
xmlStringBuilder.append("<?xml version="1.0"?> <class> </class>");
ByteArrayInputStream input = new ByteArrayInputStream(
xmlStringBuilder.toString().getBytes("UTF-8"));
Document doc = builder.parse(input);
[/java]
Step-4: Here, the root element have to be extracted.
[java]Element root = document.getDocumentElement();[/java]
Step-5: The attributes and sub-elements are tested.
[java]
//returns specific attribute
getAttribute("attributeName");
//returns a Map (table) of names/values
getAttributes();
[/java]
[java]
//returns a list of subelements of specified name
getElementsByTagName("subelementName");
//returns a list of all child nodes
getChildNodes();
[/java]
If kept all the above steps at once, below is the input XML document that has to be parsed.
[xml]<?xml version="1.0"?>
<class>
<student rollno="393">
<firstname>John</firstname>
<lastname>Mike</lastname>
<nickname>Jom</nickname>
<marks>85</marks>
</student>
<student rollno="493">
<firstname>Rafeal</firstname>
<lastname>Nadal</lastname>
<nickname>Rafa</nickname>
<marks>95</marks>
</student>
<student rollno="593">
<firstname>Samuel</firstname>
<lastname>Johnson</lastname>
<nickname>Sam</nickname>
<marks>90</marks>
</student>
</class>[/xml]
DomParserDemo.java:
[java]
package com.splessons.xml;
import java.io.File;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.w3c.dom.Node;
import org.w3c.dom.Element;
public class DomParserDemo {
public static void main(String[] args){
try {
File inputFile = new File("input.txt");
DocumentBuilderFactory dbFactory
= DocumentBuilderFactory.newInstance();
DocumentBuilder dBuilder = dbFactory.newDocumentBuilder();
Document doc = dBuilder.parse(inputFile);
doc.getDocumentElement().normalize();
System.out.println("Root element :"
+ doc.getDocumentElement().getNodeName());
NodeList nList = doc.getElementsByTagName("student");
System.out.println("----------------------------");
for (int temp = 0; temp < nList.getLength(); temp++) {
Node nNode = nList.item(temp);
System.out.println("\nCurrent Element :"
+ nNode.getNodeName());
if (nNode.getNodeType() == Node.ELEMENT_NODE) {
Element eElement = (Element) nNode;
System.out.println("Student roll no : "
+ eElement.getAttribute("rollno"));
System.out.println("First Name : "
+ eElement
.getElementsByTagName("firstname")
.item(0)
.getTextContent());
System.out.println("Last Name : "
+ eElement
.getElementsByTagName("lastname")
.item(0)
.getTextContent());
System.out.println("Nick Name : "
+ eElement
.getElementsByTagName("nickname")
.item(0)
.getTextContent());
System.out.println("Marks : "
+ eElement
.getElementsByTagName("marks")
.item(0)
.getTextContent());
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
[/java]
The javax.xml.Parsers.DocumentBuilderFactory class characterizes a processing plant API that empowers applications to acquire a parser that produces DOM protest trees from XML records.
Output:
[java]
Root element :class
----------------------------
Current Element :student
Student roll no : 393
First Name : John
Last Name : Mike
Nick Name : Jom
Marks : 85
Current Element :student
Student roll no : 493
First Name : Rafeal
Last Name : Nadal
Nick Name : Rafa
Marks : 95
Current Element :student
Student roll no : 593
First Name : Samuel
Last Name : Johnson
Nick Name : Sam
Marks : 90
[/java] Key Points
- DOM as a tree structure which is called as node-tree structure.
- Nodes in a document have parent-child relationship.