



 Description
Description
To eliminate duplicate values in a column use SQL Distinct clause.
Conceptual
figure
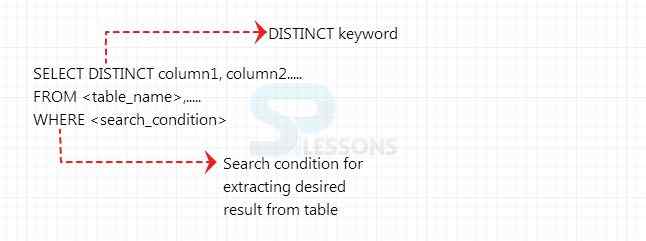
Syntax
Select DISTINCT <column_ name> from <table_name>;
Table_name=> Any accurate table.
column_name => The condition that one can perform on a column by using distinct clause.
Examples
By viewing the below example, the concept of SQL Distinct clause can be easily understood.
[c]
sql> select * from employee;
+--------+-------+-------+--------+
| emp_id | ename | salary| deptno |
+--------+-------+-------+--------+
| 1001 | mike | 12000 | 10 |
| 1002 | rambo | 13000 | 20 |
| 1003 | kate | 14000 | 10 |
| 1003 | jeo | 14000 | 20 |
| 1003 | finn | 14000 | 30 |
+--------+-------+-------+--------+
5 rows in set (0.00 sec)
sql> select distinct deptno from employee;
+--------+
| deptno |
+--------+
| 10 |
| 20 |
| 30 |
+--------+
3 rows in set (0.00 sec)[/c]
The above example tells that, when distinct clause operation is performed on a column deptno, then it displays the values of jeo, finn, and kate as they have the maximum salary and automatically remove duplicate values of mike and rambo as they having minimum salary.
Key Points
- SQL Distinct Clause - Distant clause is used to eliminate duplicate values.