



 Description
Description
Before starting the first program with Lucene user need to have good knowledge in coding and also in IDE's such as Eclipse why because most of the developers will use Eclipse as the IDE. Already in previous chapters Splessons have covered the topics regarding the installation steps for the JDK and Eclipse. The following is the project structure.
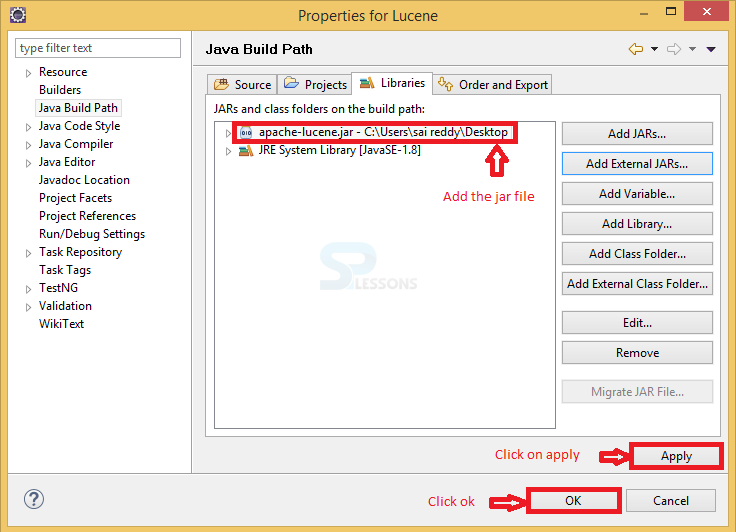
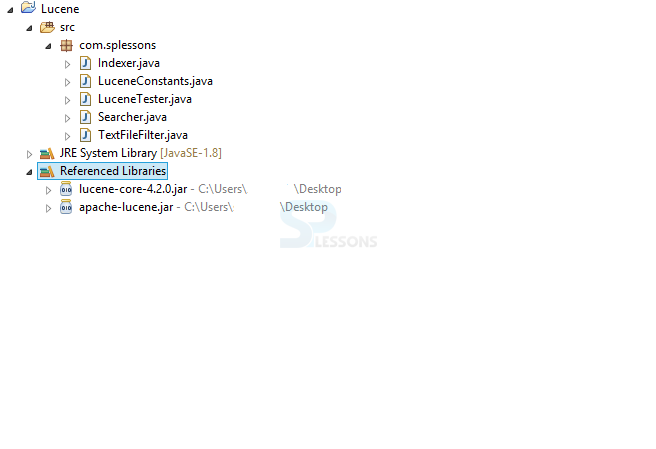 In the above structure, the developer has created the package called com.splessons, under this package all the source files have been placed. Import the all the required jar files as follows.
In the above structure, the developer has created the package called com.splessons, under this package all the source files have been placed. Import the all the required jar files as follows.
 LuceneConstants.java
[java]package com.splessons;
public class LuceneConstants {
public static final String CONTENTS="contents";
public static final String FILE_NAME="filename";
public static final String FILE_PATH="filepath";
public static final int MAX_SEARCH = 10;
}[/java]
TextFileFilter.java
[java]package com.splessons;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}[/java]
Indexer.java
[java]package com.splessons;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException{
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
public void close() throws CorruptIndexException, IOException{
writer.close();
}
private Document getDocument(File file) throws IOException{
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS,
new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException{
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException{
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.numDocs();
}
}[/java]
This Lucene - StandardAnalyzer is prepared for dealing with names, email address et cetera. It lowercases each token and ousts typical words and highlight expecting any.
Lucene - SimpleAnalyzer is utilized to spilt the substance in a record in perspective of non-letter characters and after that lowercase them.
Searcher.java
This class is utilized to seek the lists made by Indexer to look the asked for substance.
[java]
package com.splessons;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException{
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException{
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException{
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException{
indexSearcher.close();
}
}[/java]
Looking for methodology is again one of the middle handiness gave by Lucene. It's stream resemble that of requesting system. Major request of Lucene can be made using taking after classes which can moreover be named as foundation classes for all chase related operations.
LuceneTester.java
This class is utilized to test the ordering and hunt ability of Lucene library. Ordering procedure is one of the center usefulness gave by Lucene.
[java]package com.splessons;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "D:\\Splessons\\Lucene\\Index";
String dataDir = "D:\\Splessons\\Lucene\\Data";
Indexer indexer;
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException{
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
private void search(String searchQuery) throws IOException, ParseException{
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime));
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "
+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}[/java]
Output: Now compile the code result will be as follows.
[java]Indexing D:Splessons\Lucene\Data\record1.txt
Indexing D:\Splessons\Lucene\Data\record10.txt
Indexing D:\Splessons\Lucene\Data\record2.txt
Indexing D:\Splessons\Lucene\Data\record3.txt
Indexing D:\Splessons\Lucene\Data\record4.txt
Indexing D:\Splessons\Lucene\Data\record5.txt
Indexing D:\Splessons\Lucene\Data\record6.txt
Indexing D:\Splessons\Lucene\Data\record7.txt
Indexing D:\Splessons\Lucene\Data\record8.txt
Indexing D:\Splessons\Lucene\Data\record9.txt
10 File indexed, time taken: 109 ms
1 documents found. Time :0
File: D:Splessons\Lucene\Data\record4.txt[/java]
LuceneConstants.java
[java]package com.splessons;
public class LuceneConstants {
public static final String CONTENTS="contents";
public static final String FILE_NAME="filename";
public static final String FILE_PATH="filepath";
public static final int MAX_SEARCH = 10;
}[/java]
TextFileFilter.java
[java]package com.splessons;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}[/java]
Indexer.java
[java]package com.splessons;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException{
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
public void close() throws CorruptIndexException, IOException{
writer.close();
}
private Document getDocument(File file) throws IOException{
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS,
new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException{
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException{
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.numDocs();
}
}[/java]
This Lucene - StandardAnalyzer is prepared for dealing with names, email address et cetera. It lowercases each token and ousts typical words and highlight expecting any.
Lucene - SimpleAnalyzer is utilized to spilt the substance in a record in perspective of non-letter characters and after that lowercase them.
Searcher.java
This class is utilized to seek the lists made by Indexer to look the asked for substance.
[java]
package com.splessons;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Searcher {
IndexSearcher indexSearcher;
QueryParser queryParser;
Query query;
public Searcher(String indexDirectoryPath)
throws IOException{
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
indexSearcher = new IndexSearcher(indexDirectory);
queryParser = new QueryParser(Version.LUCENE_36,
LuceneConstants.CONTENTS,
new StandardAnalyzer(Version.LUCENE_36));
}
public TopDocs search( String searchQuery)
throws IOException, ParseException{
query = queryParser.parse(searchQuery);
return indexSearcher.search(query, LuceneConstants.MAX_SEARCH);
}
public Document getDocument(ScoreDoc scoreDoc)
throws CorruptIndexException, IOException{
return indexSearcher.doc(scoreDoc.doc);
}
public void close() throws IOException{
indexSearcher.close();
}
}[/java]
Looking for methodology is again one of the middle handiness gave by Lucene. It's stream resemble that of requesting system. Major request of Lucene can be made using taking after classes which can moreover be named as foundation classes for all chase related operations.
LuceneTester.java
This class is utilized to test the ordering and hunt ability of Lucene library. Ordering procedure is one of the center usefulness gave by Lucene.
[java]package com.splessons;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
public class LuceneTester {
String indexDir = "D:\\Splessons\\Lucene\\Index";
String dataDir = "D:\\Splessons\\Lucene\\Data";
Indexer indexer;
Searcher searcher;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
tester.search("Mohan");
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException{
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
private void search(String searchQuery) throws IOException, ParseException{
searcher = new Searcher(indexDir);
long startTime = System.currentTimeMillis();
TopDocs hits = searcher.search(searchQuery);
long endTime = System.currentTimeMillis();
System.out.println(hits.totalHits +
" documents found. Time :" + (endTime - startTime));
for(ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.getDocument(scoreDoc);
System.out.println("File: "
+ doc.get(LuceneConstants.FILE_PATH));
}
searcher.close();
}
}[/java]
Output: Now compile the code result will be as follows.
[java]Indexing D:Splessons\Lucene\Data\record1.txt
Indexing D:\Splessons\Lucene\Data\record10.txt
Indexing D:\Splessons\Lucene\Data\record2.txt
Indexing D:\Splessons\Lucene\Data\record3.txt
Indexing D:\Splessons\Lucene\Data\record4.txt
Indexing D:\Splessons\Lucene\Data\record5.txt
Indexing D:\Splessons\Lucene\Data\record6.txt
Indexing D:\Splessons\Lucene\Data\record7.txt
Indexing D:\Splessons\Lucene\Data\record8.txt
Indexing D:\Splessons\Lucene\Data\record9.txt
10 File indexed, time taken: 109 ms
1 documents found. Time :0
File: D:Splessons\Lucene\Data\record4.txt[/java]
Key Points
- Query is a unique class and contains different utility techniques and is the parent of a wide range of queries.
- TermQuery is the most generally utilized query protest and is the establishment of numerous mind boggling queries that lucene can make utilization of.